

-
Informatique
www.indg.fr
-
Concepteur en informatique de gestion
Expert en méthodologie de l'informatique
25 ans d'expertise en informatique
Méthodes
de programmation
(Consultant indépendant pour les maitrises d'oeuvre)
4 méthodes de programmation détaillées
L'histoire des langages informatiques
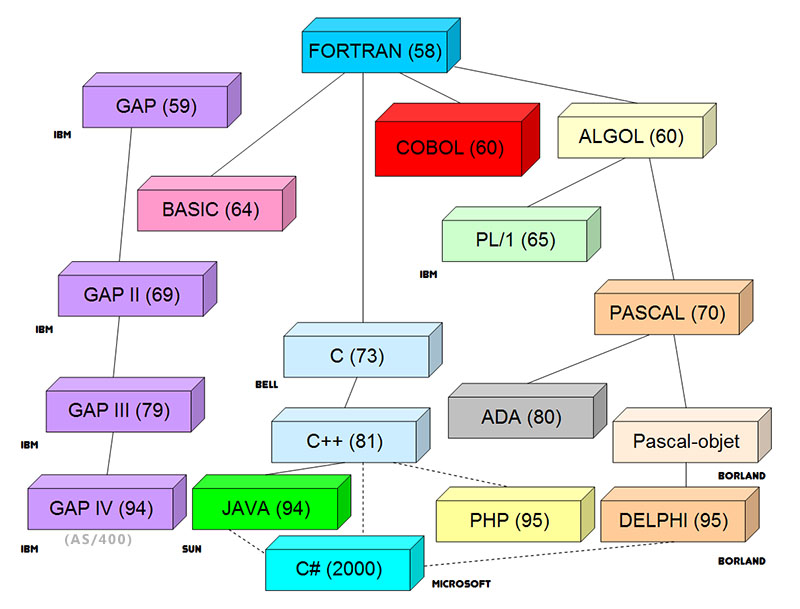
L'histoire des langages informatique
L'informatique de gestion a connu un énorme essor dans les années 60. Avec le développement des mainframes IBM, des langages informatique dédiés à la gestion se sont répandus dans les plus grandes entreprises mondiales. Jusque là on ne connaissait que l'assembleur et le Fortran, ce dernier étant utilisé par les scientifiques. Le langage LISP apparait en 1958 ; il s'agit d'un langage de programmation fonctionnelle très spécifique et peu utilisé. Mais c'est surtout l'ALGOL, qui date de 1960, qui est à l'origine de nombreux langages.
IBM lance de son côté le RPG en 1959 (langage GAP) qui va ensuite évoluer vers le GAP 2 en 1969. Ce langage très orienté cartes perforées finira sa vie sur l'AS/400. Mais c'est bien sur la naissance du COBOL (COmmon Business Oriented Langage) en 1960 qui sera la plus déterminante. Le Cobol a été élaboré par le comité CODASYL (COnference on DAta SYstems Languages). IBM ne sort le PL/1 (Programming Language number One) qu'en 1965. Mais il est déjà trop tard et le Cobol a pris une longueur d'avance sur ses concurrents.
Une nouvelle génération de langages
Ces nouveaux langages découlent soit du Fortran, soit de l'Algol. Le basic est apparu en 1964, le Pascal en 1970 et le langage C en 1973.
L'un des premiers langages orienté objet est Smalltalk. Il date
de 1972. Mais il faut attendre les années 80 pour voir foisonner
ce types de langages : Ada en 1980, C++ en 1981, Eiffel en 1985.
Perl voit le jour en 1987 et Python en 1991. Java ne date que de 1994
et PHP de 1995, tout comme javascript. Ces trois derniers langages se sont développés essentiellement avec l'avènement d'internet ou ont tout simplement été créé pour le WEB.
C# est relativement récent puisqu'il a été
introduit en l'an 2000.
Même si l'informatique de gestion est en constante
évolution depuis ces dernières années, ce sont
surtout les programmes procéduraux qui prédominent, et en
particulier le COBOL.
Un besoin d'homogénéité
Le GAP et l'assembleur ne posent pas de problèmes de
programmation à cause de leur rigidité. Les langages
récents apportent une certaine structuration associée
à une souplesse. Mais ils apportent leurs propres
méthodes avec eux. La plupart sont des langages
évènementiels, c'est à dire qu'ils
fonctionnent par évènement déclencheur. Par
exemple un clic de souris va déclencher une certaine fonction.
Les deux langages qui ont posé le plus de problèmes aux
développeurs sont finalement les deux langages les plus
utilisés en informatique de gestion dans les années 60 et
70 : le COBOL et le PL/1.
En effet, ces langages proposent une panoplie complète
d'instructions pour manipuler les données.
Mais il leur manque
une rigueur de programmation ce qui peut amener un programmeur à
développer à tort et à travers, de façon
empirique et désordonnée, sans aucune méthode, ce
qui va rendre les programmes très rapidement in-maintenables.
Beaucoup de spécialistes en algorithmie se
sont penchés
sur ces problèmes et ont préconisé
différentes solutions. A cette
époque, la réflexion méthodologique bat son plein,
avec au cœur du sujet la programmation structurée.
Ne pas confondre méthodes d'analyse et méthodes de programmation
Tout d'abord il ne faut pas faire la confusion entre méthode d'analyse et méthode de programmation.
Une méthode d'analyse concerne la conception d'une application alors qu'une méthode de programmation est de la pure algorithmie. L'analyste et le développeur sont bien souvent deux personnes différentes. La finalité du programmeur est de produire un programme qui fonctionne tel que spécifié mais également un programme qui va pouvoir facilement évoluer. L'analyste pense en termes d'applications qui regroupent plusieurs programmes s'articulant entre-eux. Le code n'est pas sa préoccupation.
Quelques méthodes d'analyses très connues
La
méthode Warnier
C'est au début des années 1970 que
Jean-Dominique WARNIER, alors ingénieur
informaticien chez Bull,
propose ses méthodes novatrices en matière d'organisation,
de structuration et de conception des systèmes informatiques. Il fut lauréat en 1974 de l'Engineer And Scientist
Award. On
lui doit la fameuse méthode L.C.P. (Logique de
Construction de
programmes) qui s'apparente bien plus à une méthode d'analyse
qu'à une méthode de programmation. Le principe de la méthode LCP est d'effectuer une
analyse séparée des FLE et des FLS, les fichiers logiques
d'entrée et les fichiers logiques de sortie. Ce sont en fait les
données en sortie qui vont conditionner les données en
entrée. Une génération entière
d'informaticiens a été formée grâce à
la méthode WARNIER. Elle était très
utilisée en France et en Belgique, principalement pour former
les étudiants. Ensuite elle n'était plus vraiment
utilisée en entreprise car elle alourdissait le temps de travail
des informaticiens pour réaliser leur algorithme. Mais les bases
de cette méthode apportent une approche logique de la
conception d'applications. C'est d'ailleurs cette
méthode LCP
qui se retrouve à la source de plusieurs autres méthodes
plus évoluées ou de générateurs
d'applications automatiques. L'œuvre de J.D. Warnier a
eu un impact au niveau mondial qui marque encore les sciences
informatiques et a laissé son empreinte dans le Génie
logiciel et les approches Objet.
La
méthode Merise est une méthode d'analyse d'origine
française du milieu des années 80. Elle est très
complète mais aussi très
complexe et peu d'entreprises l'utilisent dans sa globalité.
UML est une méthode d'analyse pour les
applications orientées objet.
La méthode RAD.
La méthode AGILE.
La méthode Yourdon.
Les méthodes de programmation
Qu'est-ce qu'un langage procédural ?
Les Langages Orientés Objets possédant leurs propres
méthodes, je vais m'intéresser ici uniquement aux
méthodes utilisées en programmation utilisant les
langages procéduraux.
Un langage procédural est un langage qui
exécute des instructions (regroupées en
procédures) les unes
à la suite des autres. Par opposition, un langage
déclaratif ne contient pas d'instructions. On déclare ce
que l'on souhaite obtenir et c'est la machine qui trouve le meilleur
moyen pour fournir le résultat. Le SQL est un langage
déclaratif, tout comme PROLOG (utilisé en intelligence
artificielle).
Les langages procéduraux sont souvent appelés langages
impératifs car on impose à la machine tel ou tel
type de traitement. Les langages procéduraux peuvent être
séquentiels, quand les instructions sont codées et
exécutées en séquence, ou bien modulaires quand
les instructions sont regroupées dans des fonctions ou
procédures appelées routines ou sous-programme. N'importe
quelle fonction/procédure peut être appelée depuis
n'importe quel endroit du programme, y compris à
l'intérieur d'autres procédures ou de la procédure
qui s'appelle elle-même. C'est cette dernière utilisation
qui s'appelle la récursivité.
Dans un langage procédural il y a souvent un mélange
entre programmation séquentielle et
programmation procédurale. C'est la méthode de
programmation qui va imposer artificiellement au programmeur
la façon de coder. Même dans les langages plus modernes
tels que PHP ou Java, il est possible de développer en pur
"objet" ou de faire de la programmation procédurale
séquentielle.
Certains langages procéduraux utilisent des procédures
qui deviennent des éléments du langage. Il suffit
d'écrire la nom de la procédure pour que celle-ci soit
exécutée comme si c'était devenu un mot
réservé du langage. C'est le cas en Pascal ou en C. Le
Cobol et le Basic utilisent respectivement les instructions PERFORM et
GOSUB pour débrancher l'exécution séquentielle du
programme vers une routine (sous-programme) et ensuite revenir à
l'endroit d'où on était parti. L'instruction GO TO du
Cobol, ou GOTO du Basic, effectue elle aussi un débranchement
mais sans intention de revenir.
Les procédures peuvent être regroupées dans un module
externe au programme. On les appelle alors des sous-programmes
ou tout simplement des modules. Les modules sont des programmes qui ne
sont pas utilisés en tant que programme principal. Ils utilisent
une zone de communication qui contient les paramètres en
entrée. Ils retournent au programme principal qui les a
appelé les résultats en sortie, via la même zone
d'échange. Les sous-programmes externes ont la
faculté d'être disponibles pour tous les programmes qui
souhaitent les appeler.
Dans une application utilisant énormément de
sous-programmes
externes, on a affaire à une méthode de
programmation dite modulaire.
L'intérêt des modules est de ne pas avoir à recoder
la même chose dans plusieurs programmes différents. Mais
ça présente également des inconvénients, en particulier en ce qui concerne les performances.
Pourquoi introduire des méthodes de programmation ?
Quand on utilise des sous-programmes internes ou des
débranchements intempestifs à outrance, on arrive
très vite à rendre un programme illisible. C'est ce qu'on
appelle un « sac de nouilles » ou encore une « usine
à gaz ». Un programmeur qui ne connait pas le programme
sera très gêné pour le faire évoluer et y
coder ses modifications. Il est alors facile d'introduire
involontairement des bugs. Le réflexe sera alors de coder ses
évolutions dans un coin et d'utiliser encore plus de
débranchements ce qui rendra le programme encore plus complexe
et moins maintenable par les programmeurs suivants.
Exemple (à ne pas suivre) :
Il s'est donc très rapidement trouvé nécessaire de mettre un peu d'ordre dans tout cela. Sans parler de méthode de programmation, le minimum est la structuration des données en entrée. Ensuite il faut également structurer les processus d'une application. Tout ce travail est à la charge de l'analyste concepteur et sa démarche repose sur quelques grands principes :
- Découper le processus en tâches plus simples.
- Chaque tâche doit avoir un rôle précis. Il faut éviter de mélanger plusieurs tâches différentes dans le même programme.
- S'assurer que les données arrivent dans un ordre optimum pour être traitées séquentiellement par le programme.
1) Trier le fichier des commandes par numéro d'article
2) Enrichir le fichier des commandes avec des informations provenant du fichier article
3) Trier le fichier enrichi par numéro de client
4) Enrichir le fichier avec des informations provenant du fichier client
5) Programme de calcul de la facturation, produisant en sortie le fichier destiné à l'édition des factures ainsi que les différents fichiers destinés à la comptabilité
6) Programme de mise à jour de la comptabilité
7) Programme d'édition des factures.
Dans ce processus on s'aperçoit qu'il est facile d'ajouter de nouvelles fonctionnalités en intercalant simplement de nouveaux programmes qui auront chacun une finalité propre. Ces programmes ne devraient pas être compliqués outre mesure.
On pourrait également imaginer que toute la facturation soit réalisée dans un seul et unique programme qui serait une véritable usine à gaz.
Une autre chose importante à prendre en compte est la reprise en cas d'erreur. Avec le processus décrit ci-dessus, si un dysfonctionnement intervient lors de la dernière phase, l'édition, il suffit de corriger le programme d'édition et de relancer le traitement de la phase 7 sans avoir à refaire tout le calcul de la facturation.
Dans ce processus on peut remarquer une chose importante : les tris.
Les tris sont très importants car ils vont minimiser les accès disques. Dans tout système informatique, le plus coûteux en performance correspond toujours aux I/O (Input/Output = Entrées/Sorties). Moins on en fait et mieux on se porte.
Les données triées vont permettre d'écrire des programmes qui utilisent ce qu'on appelle des « ruptures ». Une rupture est un changement dans l'un des critères de tri. On sera par exemple en rupture client quand on rencontre le premier article commandé par un nouveau client. On sera également en rupture client quand on rencontre le dernier article de sa commande. On parle donc de « rupture première » et de « rupture dernière » concernant un critère.
Ce qu'apporte la méthode Warnier en programmation ?
Ce qu'il faut retenir de la méthode Warnier, et de toutes les
autres méthodes de programmation, se résume en trois
points :
- l’analyse de la structure des données de sortie permet de construire la structure des données d’entrées d’un programme,
- la structure du programme correspond très exactement à la structure des données d’entrées,
- toute procédure peut s’exprimer avec trois structures élémentaires qui sont la séquence, la répétitive et l'alternative.
- Trouver la structure du programme
- Recenser les instructions nécessaires (par type
d’instruction)
- Ranger chaque instruction à sa juste place.
D'autres penseurs vont imaginer différentes méthodes qui possèdent chacune leurs avantages et leurs inconvénients. A vous de choisir votre méthode préférée. L'important est qu'une fois que vous aurez choisi votre méthode vous devez vous attacher à la suivre pour faire du systématique et rendre le développement de programmes « industriel ». Le programmeur qui utilise une méthode n'a plus à se reposer sans cesse les mêmes questions d'un programme à l'autre. Après seulement quelques programmes réalisés il aura ses modèles, ses squelettes types en fonction du type de programme à écrire.