

-
Informatique
www.indg.fr
-
Prestation de services en informatique Expert Pacbase DB2
et réalisation professionnelle de Sites Internet
25 ans d'expérience en informatique
informatiques
(Consultant Indépendant Expert Pacbase DB2)
Base de données
Qu'est-ce qu'une base de données ? Définition

Une base de données est un ensemble de fichiers organisés avec des liens entre-eux qui permettent de hiérarchiser et de retrouver l'information plus facilement en utilisant des indexes et des langages de restitution évolués.
Les bases de données les plus utilisées sur Système Mainframe (Gros systèmes) sont DB2 et Oracle. Pour le web on utilise généralement MySQL. Il s'agit de bases de données relationnelles. Un système de bases de données est géré par ce qu'on appelle un SGBD (Système de Gestion de Bases de Données).
Le langage SQL
Le langage d'interrogation des bases de données le plus répendu est SQL. Il permet de faire des requêtes en combinant différentes informations qui peuvent provenir de plusieurs fichiers.
Dans un système de bases de données relationnelles les liens entre les fichiers sont effectués par l'intermédiaire de relations qui existent sur un critère particulier (un ou plusieurs champs). On peut avoir ainsi une base de données "clients" et une base de données "commandes". La relation entre "commandes" et "clients" sera effectuée par l'intermédiaire du numéro de client. Une autre relation peut être effectuée avec la base de données "articles" sur le numéro d'article. Une requête peut interroger les trois bases à la fois pour obtenir la liste des désignations d'articles commandés par exemple par tous les clients d'un certain département donné.
Il existe d'autres systèmes de gestion de bases de données qui ne sont pas relationnels. On trouve par exemple les bases de données de type "CODASYL réseau", les bases de données hiérarchiques, etc...
Structuration de l'information
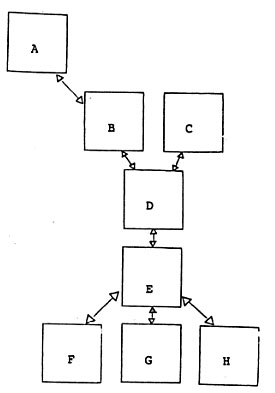
Les bases de données permettent de mieux structurer l'information et d'éviter les redondances et les divergences.
Outre cette structuration logique des données, l'un des énorme avantage d'une base de données est que l'accès aux informations qu'elle contient peut être partagé simultanément entre plusieurs utilisateurs et entre plusieurs programmes. Avec un système de fichiers il est courant de constater qu'en cas de mise à jour de ce fichier par un programme l'ensemble du fichier est bloqué et les autres utilisateurs doivent attendre la fin de la mise à jour. C'est ce comportement qui explique l'importance des traitements batch dans les années 60-70-80. Il fallait effectuer une coupure des terminaux pour suspendre toutes les mises à jour pendant que les traitements quotidiens, de comptabilité notamment, étaient effectués bien souvent pendant la nuit entière.
Un SGBD possède une gestion beaucoup plus fine des données en utilisant un système complexe de verrous logiques qui permet de ne bloquer que l'information en cours de mise à jour mais de laisser libre en lecture les autres enregistrements de la base de donnée.
Le SGBD se charge de toutes les tâches d'accès à la
base de données et de sa structuration, son stockage, son
indexation, sa maintenance. Il gère la lecture concurrente, la
mise à jour exclusive à l'aide de verrous, l'insertion de
données, la suppression d'enregistrements en garantissant la
mise à jour de tous les objets liés (indexes, ...).
Historique des bases de données

L'organisation classique en fichiers a perduré jusqu'à la fin des années 1960. C'est alors qu'on a vu apparaître les premiers systèmes de bases de données. Il s'agissait de systèmes réseaux hiérarchiques. Ces bases de données étaient accompagnées de langages navigationnels pour les exploiter. Ils étaient basés sur les modèles Hiérarchique et Réseau. C’est la Première Génération des SGBD commerciaux parmi lesquels on trouve le CODASYL, IMS, IDS 2, IMS 2, TOTAL, IDMS ... Les LMD sont les langages de manipulation de données navigationnels. Ils permettent de naviguer à travers le réseau de la base de donnée en suivant des liens de type "père/fils".
Le début des années 1980 voit l'apparition de la seconde génération de systèmes de gestion de bases de données, il s'agit des SGBD relationnels. Le but était d'enrichir et de simplifier l'accès des données aux utilisateurs avec des langages déclaratifs simples à utiliser. Les SGBD de deuxième génération débouchent sur le modèle relationnel et utilisent un langage de manipulation non-procédural . Il ne s'agit plus de suivre des liens, de réclamer des accès en lecture, d'effectuer des mises à jour unitaires. Ces nouveaux langages s'utilisent sous forme de requête et une requête d'accès à une base de donnée relationnelle peut impacter un nombre très élevé d'occurrences. On voit donc apparaître dans les années 1980 des SGBD relationnels tels que ORACLE, INGRES, INFORMIX, SYBASE, DB2, RDB, SQL Server en mode Client/Serveur et même le célèbre DBASE III+ sur micro-ordinateur.
La dernière génération de SGBD date des années 1990 avec des systèmes de base de données orienté objet. Il faut ensuite attendre les années 2010 pour qu'arrive le CLOUD et les bases de données qui l'accompagnent.
Rôle des SGBD
Un SGBD permet de gérer des données structurées et persisitantes de façon intègre, fiable, concurrente et efficace. Pour ce qui est de la structuration il offre un système de typage des données (caractères, nombres entiers, nombres décimaux, dates, ...). La persistance des données consiste à enregistrer ces données sur des supports de stockage comme des disques durs. L'intégrité des informations est assurée par des systèmes de sécurité et des systèmes de "vues" qui permettent de présenter les informations à des utilisateurs différents ayant des habilitations distinctes de manière différente mais homogène. La fiabilité est le résultats de mécanismes de contraintes, d'intégrité référentielle, de sécurisation, d'habilitations, de points de synchronisation et de rollback, etc...
Malgré toutes ces fonctionnalités complexes, les SGBD se doivent d'offrir aux utilisateurs des temps de réponse dignes de ce nom et d'être performants. Ils utilisent abondamment des indexes qui permettent d'optimiser les requêtes, du cache en mémoire ou dans des bases temporaires.
Manipulation des données dans un SGBD relationnel
Contrairement aux bases de données de type
CODASYL Réseau où la manipulation nécessitait une
connaissance parfaite du plan de la base de donnée (qu'on
appelait dans certaines bases le « BACHMAN », du nom de
l'inventeur du réseau CODASYL), les bases de données de
type relationnel prônent l'indépendance logique des
données par rapport à leur organisation physique. Si le
CODASYL est un genre de réseau de fichiers reliés
entre-eux par des liens, une base de données relationnelle se
présente comme un ensemble de vues où les indexes sont
transparents pour l'utilisateur et le développeur
d'applications. C'est le SGBD lui-même qui va choisir le meilleur
index à utiliser en fonction de la requête
demandée. Un
remaniement de l'organisation physique des données n'entraine
pas de modification dans les programmes. On peut ajouter une colonne
dans une table, ajouter des indexes, modifier une vue, sans avoir
à recompiler le moindre programme.
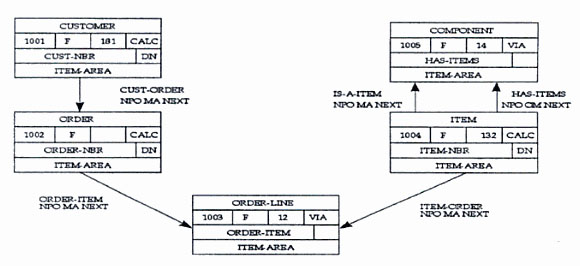
Exemple d'un diagramme de Bachman